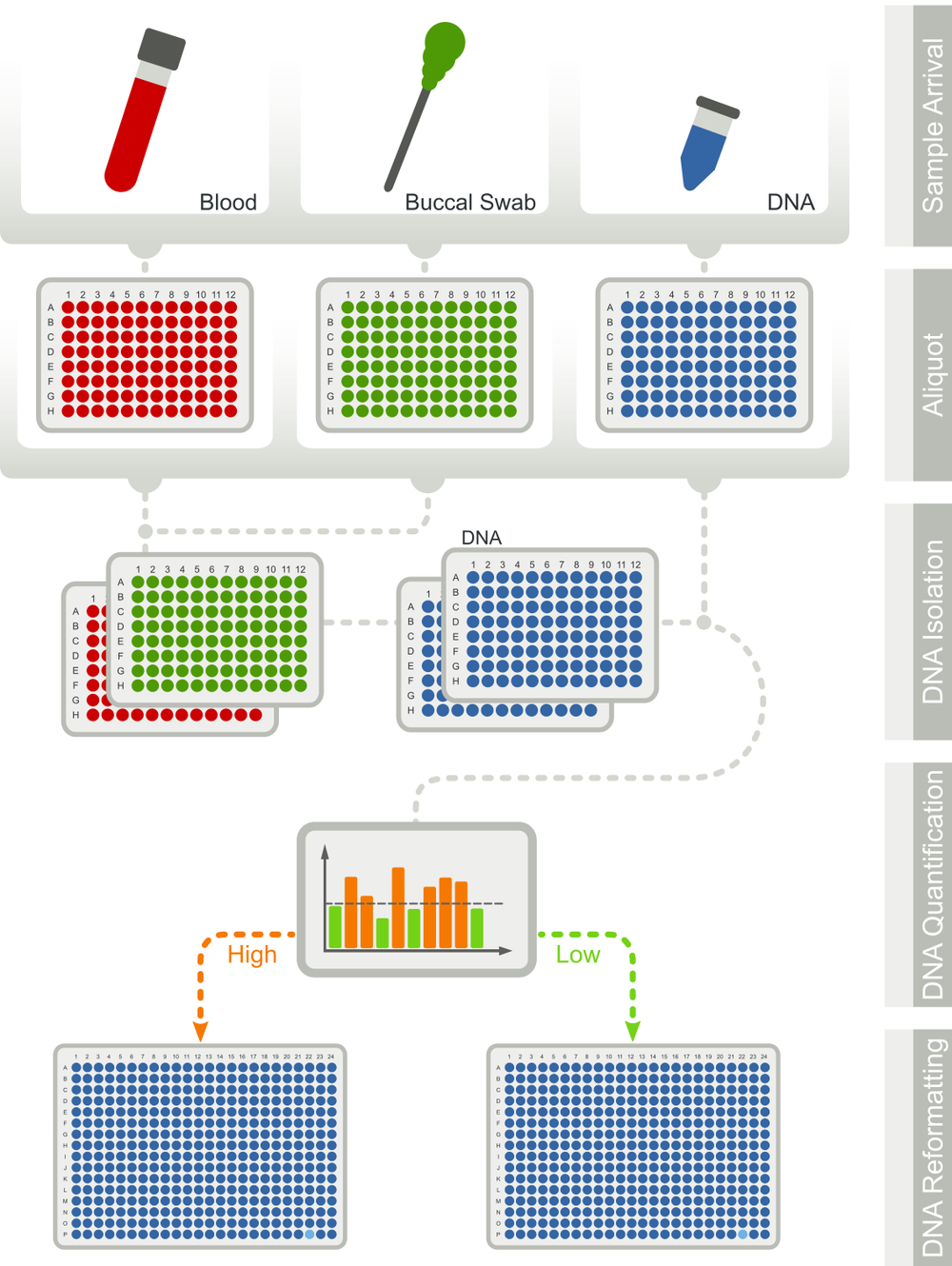
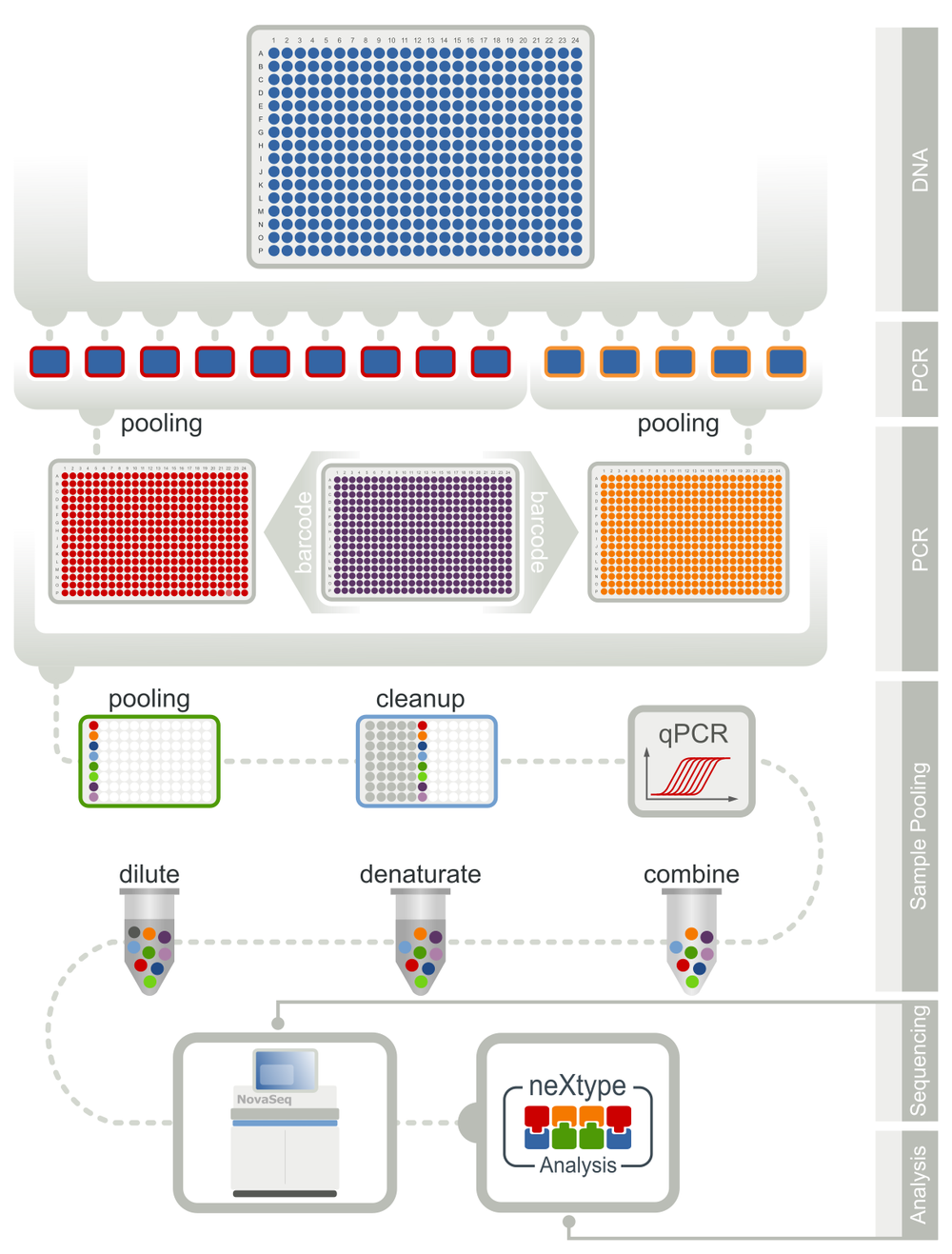
The workflow starts with the DNA isolation from buccal swabs. This is followed by the amplification of selected regions of HLA-A, HLA-B, HLA-C, HLA-DRB1, HLA-DQB1, HLA-DPB1, HLA-DPA1, HLA-DQA1, HLA-DRB3/4/5, HLA-E, MICA/B, KIR, CCR5, ABO and RhD by PCR in a 384well format. The amplification products are pooled by sample and subjected to a second PCR adding sample-specific barcodes and adaptors for sequencing. Finally, up to 15,000 samples are pooled for sequencing on an Illumina NovaSeq6000 instrument.
Sequencing data are analyzed using neXtype (Lange et al., 2014). This in-house developed software is highly scalable and implements an innovative, decision-tree-based allele matching algorithm. Furthermore, neXtype uses sophisticated scoring procedures to automatically assess the quality of typing results, thus minimizing the need for user interaction.